RabbitMQ
RabbitMQ架构
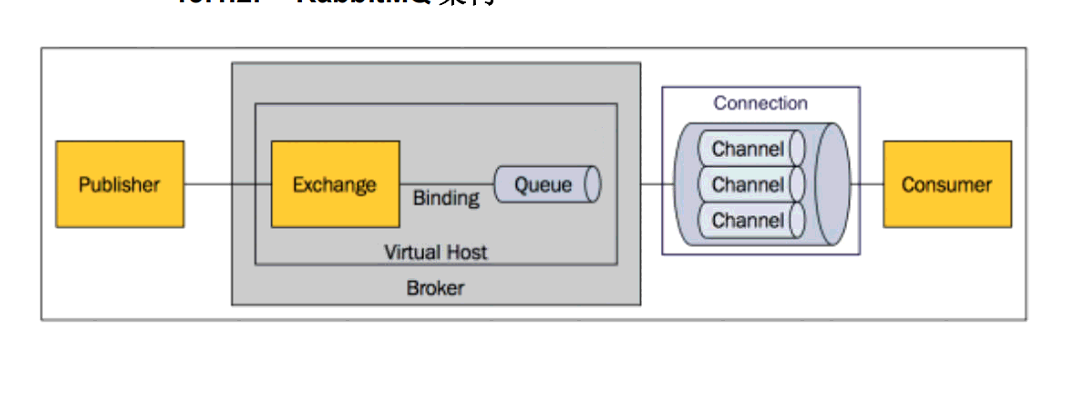
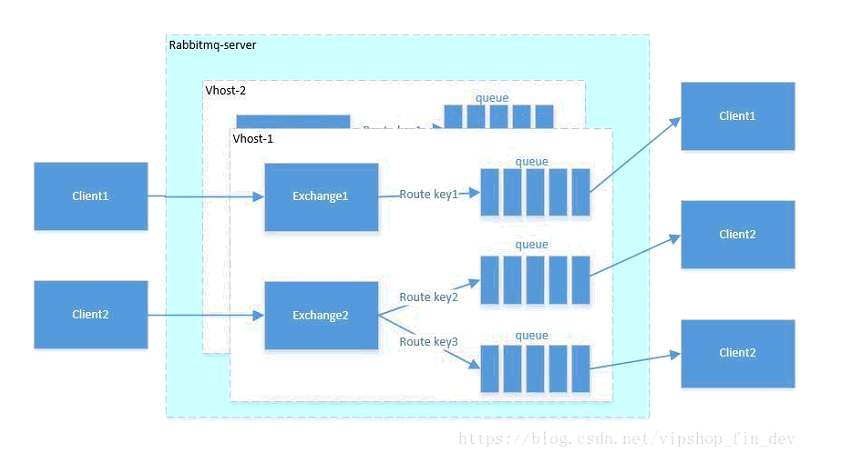
Message::消息,消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系
列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优
先权)、delivery-mode(指出该消息可能需要持久性存储)等。
Publisher:消息的生产者,也是一个向交换器发布消息的客户端应用程序。
Exchange:交换器,用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
Binding:绑定,用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连
接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
Queue:消息队列,用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息
可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
Connection:网络连接,比如一个 TCP 连接。
Channel:信道,多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的 TCP 连接内地虚
拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这
些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所
以引入了信道的概念,以复用一条 TCP 连接。
Consumer:消息的消费者,表示一个从消息队列中取得消息的客户端应用程序。
Virtual Host:虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密
环境的独立服务器域
Broker:表示消息队列服务器实体。
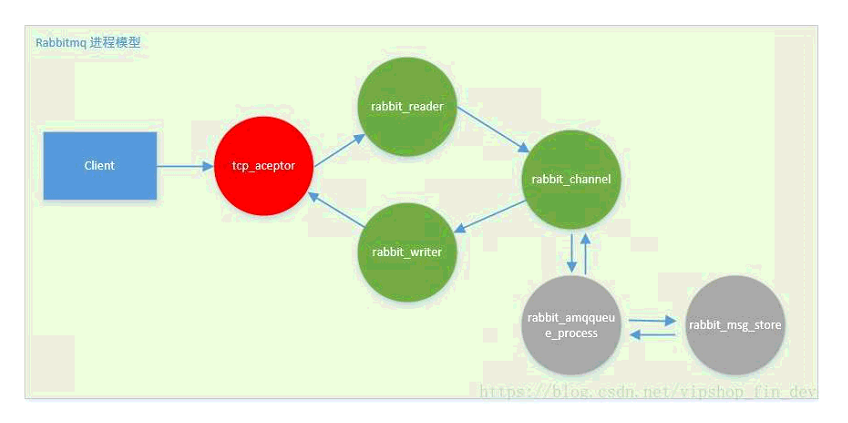
rabbitmq的进程模型是事件驱动模型(或者说反应堆模型),这是一种高性能的非阻塞io线程模型。
- tcp_acceptor:接收客户端连接,创建rabbit_reader、rabbit_writer、rabbit_channel进程。
- rabbit_reader:接收客户端连接,解析AMQP帧;
- rabbit_writer:向客户端返回数据;
- rabbit_channel:解析AMQP方法,对消息进行路由,然后发给相应队列进程。
- rabbit_amqqueue_process:是队列进程,在RabbitMQ启动(恢复durable类型队列)或创建队列时创建。
- rabbit_msg_store:负责消息持久化的进程。
在整个系统中,存在一个tcp_accepter进程,一个rabbit_msg_store进程,有多少个队列就有多少个rabbit_amqqueue_process进程,每个客户端连接对应一个rabbit_reader和rabbit_writer进程。
RabbitMQ 如何保证消息的顺序性?
拆分为多个queue,每个queue由一个consumer消费;
或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理
如何确保消息正确地发送至 RabbitMQ
将信道设置成 confirm 模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的 ID。
一旦消息被投递到目的队列后,信道会发送一个确认(ack)给生产者(包含消息唯一 ID)。
如果 RabbitMQ 发生内部错误从而导致消息丢失,会发送一条 nack(notacknowledged,未确认)消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。
当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
如何确保消息不丢失
消息持久化,当然前提是队列必须持久化
RabbitMQ 确保持久性消息能从服务器重启中恢复的方式是,将它们写入磁盘上的一个持久化日志文件,当发布一条持久性消息到持久交换器上时,Rabbit 会在消息提交到日志文件后才发送响应。一旦消费者从持久队列中消费了一条持久化消息,RabbitMQ 会在持久化日志中把这条消息标记为等待垃圾收集。如果持久化消息在被消费之前 RabbitMQ 重启,那么 Rabbit 会自动重建交换器和队列(以及绑定),并重新发布持久化日志文件中的消息到合适的队列。
如何确保消息接收方消费了消息
这部分要处理的场景是: 当消费者接收到消息后,还没处理完业务逻辑,消费者挂掉了,此时消息等同于丢失了。
为了确保消息被消费者成功消费,RabbitMQ提供了消息确认机制,主要通过显示Ack模式来实现。
默认情况下,RabbitMQ会自动把发送出去的消息置为确认,然后从内存(或磁盘)删除,但是我们在使用时可以手动设置autoAck为False的
需要注意的时,如果设置autoAck为false,也就意味者每条消息需要我们自己发送ack确认,RabbitMQ才能正确标识消息的状态。
如何避免消息重复投递或重复消费
在消息生产时,MQ 内部针对每条生产者发送的消息生成一个 inner-msg-id,作为去重的依据(消息投递失败并重传),避免重复的消息进入队列;
在消息消费时,要求消息体中必须要有一个 bizId(对于同一业务全局唯一,如支付 ID、订单 ID、帖子 ID 等)作为去重的依据,避免同一条消息被重复消费。
普通集群模式
RabbitMQ 镜像集群模式
你创建的 queue,无论元数据还是 queue 里的消息都会存在于多个实例上,然后每次你写消息到 queue 的时候,都会自动把消息到多个实例的 queue 里进行消息同步。
好处在于,你任何一个机器宕机了,没事儿,别的机器都可以用。坏处在于,第一,这个性能开销也太大了吧,消息同步所有机器,导致网络带宽压力和消耗很重!第二,这么玩儿,就没有扩展性可言了,如果某个 queue 负载很重,你加机器,新增的机器也包含了这个 queue 的所有数据,并没有办法线性扩展你的 queue
Redis
进程模型

布隆过滤器
Lua脚本
rehash
缓存雪崩
由于原有缓存失效,新缓存未到期间(例如:我们设置缓存时采用了相同的过期时间,在同一时刻出现大面积的缓存过期),所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机。从而形成一系列连锁反应,造成整个系统崩溃。
- 在批量往Redis存数据的时候,把每个Key的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,我们数据库的 id 都是1开始自增上去的,如发起为id值为 -1 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
- 最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
- 另外也有一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存击穿
缓存击穿这个跟缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞
- 若缓存的数据是基本不会发生更新的,则可尝试将该热点数据设置为永不过期。
- 若缓存的数据更新不频繁,且缓存刷新的整个流程耗时较少的情况下,则可以采用基于 redis、zookeeper 等分布式中间件的分布式互斥锁,或者本地互斥锁以保证仅少量的请求能请求数据库并重新构建缓存,其余线程则在锁释放后能访问到新缓存。
redis的过期策略以及内存淘汰机制
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据,新写入操作会报错
class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int CACHE_SIZE;
/**
* 传递进来最多能缓存多少数据
*
* @param cacheSize 缓存大小
*/
public LRUCache(int cacheSize) {
// true 表示让 linkedHashMap 按照访问顺序来进行排序,最近访问的放在头部,最老访问的放在尾部。
super((int) Math.ceil(cacheSize / 0.75) + 1, 0.75f, true);
CACHE_SIZE = cacheSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当 map中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
return size() > CACHE_SIZE;
}
如何保证缓存与数据库的双写一致性?
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统不是严格要求 “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:读请求和写请求串行化,串到一个内存队列里去。
串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
分布式锁注意事项
- 设置的key必须要有过期时间,防止崩溃时锁无法释放
- value使用唯一id标志每个客户端,保证只有锁的持有者才可以释放锁
Mysql
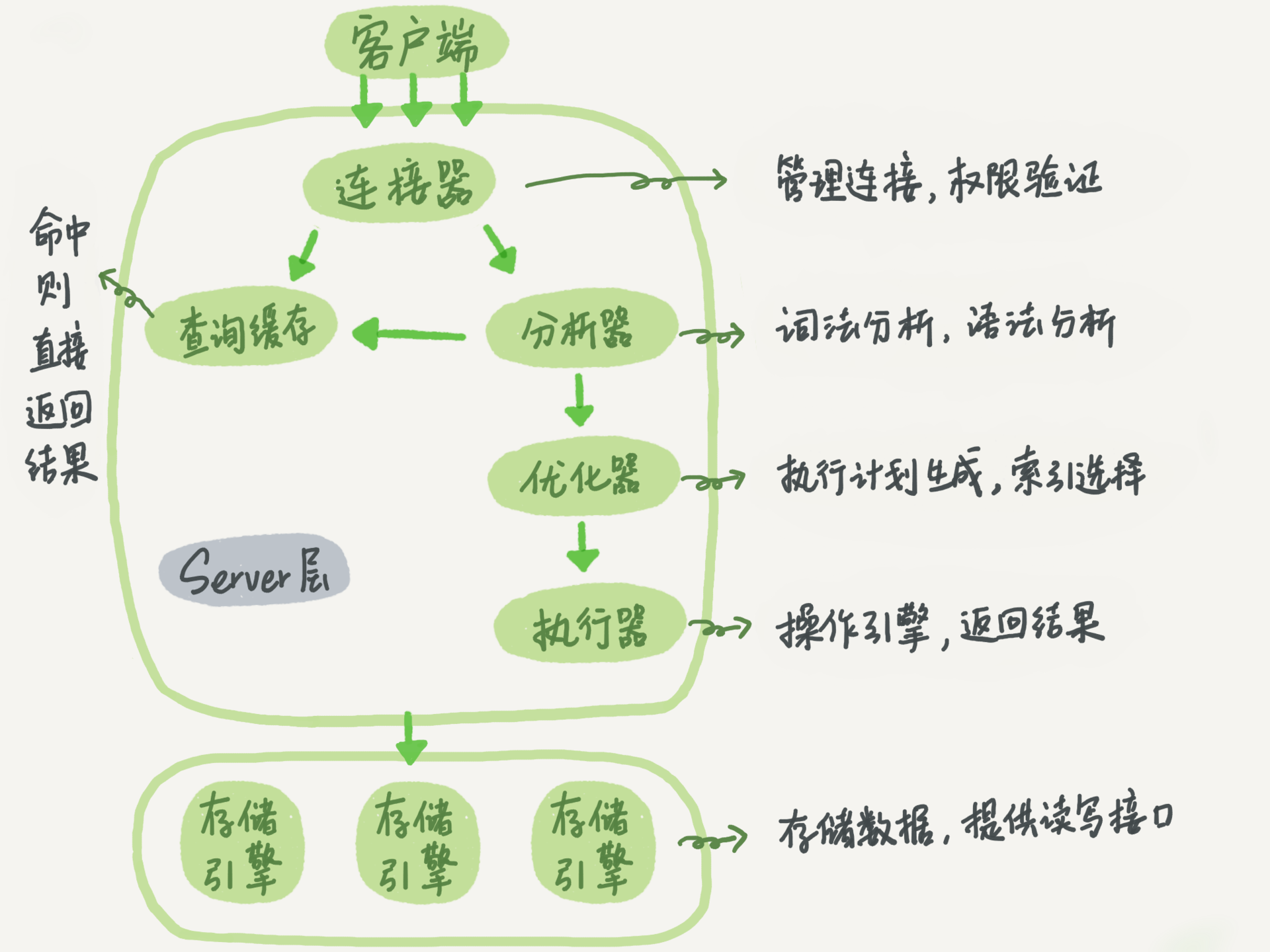
Mysql逻辑架构图
数据库事务
- 原子性:事务是一个完整的操作。事务的各步操作是不可分的(原子的);要么都执行,要么都不执行。
- 一致性:当事务完成时,数据必须处于一致状态。
- 隔离性:对数据进行修改的所有并发事务是彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务。
- 永久性:事务完成后,它对数据库的修改被永久保持,事务日志能够保持事务的永久性。
脏读、幻读、不可重复读
- 脏读 :指一个事务处理过程中读取了另一个事务未提交的数据。比如,事务A读取了事务B中尚未提交的数据。如果事务B回滚,则A读取使用了错误的数据。
- 不可重复读:对于数据库中的某个数据,一个事务范围内多次查询返回了不同的值,这是由于在查询间隔,被另一个事务修改并提交了。例如,事务 T1 在读取某一数据,而事务 T2 立马修改了这个数据并且提交事务,当事务T1再次读取该数据就得到了不同的结果,即发生了不可重复读。
- 幻读:指在一个事务读的过程中,另外一个事务可能插入(删除)了数据记录,影响了该事务读的结果。例如,事务 T1 对一个表中所有的行的某个数据项执行了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。这时,操作事务 T1 的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
数据库事务隔离级别
- Serializable(串行化): 最高级别,可避免脏读、不可重复读、幻读
- Repeatable read(可重复读): 可避免脏读、不可重复读的发生(mysql默认)
- Read committed(读已提交): 可避免脏读的发生(Oracle默认)
- Read uncommitted(读未提交): 最低级别,任何情况都无法避免
MVCC
redo log(重做日志),undo log(回滚日志), bin log(二进制日志)
InnoDB锁的特性
- 在不通过索引条件查询的时候,InnoDB使用的是表锁
- InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。
- 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论 是使用主键索引、唯一索引或普通索引,InnoDB 都会使用行锁来对数据加锁。
- 即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它 就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。
InnoDB的锁分类
- Record Lock:行锁:单个行记录上的行锁
- Gap Lock:间隙锁,锁定一个范围,但不包括记录本身
Next-Key Lock:Gap+Record Lock,锁定一个范围,并且锁定记录本身
Read committed(读已提交)仅有Record Lock
Repeatable read(可重复读)有Record Lock和Next-Key Lock
update语句执行过程
update T set c=c+1 where ID=2;
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
Sql优化
- 避免全表扫描
- 避免索引失效
- 避免排序,不能避免,尽量选择索引排序
- 避免查询不必要的字段
- 避免临时表的创建,删除
索引失效的情况
- 使用like时通配符在前
- 在查询条件中使用OR
- 对索引列进行函数运算
- MYSQL使用不等于(<,>,!=)的时候无法使用索引,会导致索引失效
- 当使用or关键字进行查询时候,只有当or两边的查询条件都是索引列时候,才使用索引
- 尽可能的使用 varchar/nvarchar 代替 char/nchar (节省字段存储空间)
- 联合索引ABC问题: Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是index (a,b,c),可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c或c进行查找 。
- 优化嵌套查询 :某些子查询可以通过join来代替。理由:join不需要在内存中创建一个临时表来存储数据。
- 使用not exist代替not in:如果查询语句使用了not in 那么内外表都进行全表扫描,没有用到索引;而not extsts 的子查询依然能用到表上的索引
in 和 exist 区别选择
in 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
因此,in用到的是外表的索引, exists用到的是内表的索引。
如果查询的两个表大小相当,那么用in和exists差别不大,
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in
回表 、覆盖索引、聚簇、非聚簇索引
- 回表:需要先定位主键值,再定位行记录的查询 叫回表
- 覆盖索引:一个索引包含所有要查询的字段的值叫覆盖索引
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,也叫辅助索引,二级索引
SQL执行计划
mysql> EXPLAIN SELECT 1;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | NULL | No tables used |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------+
- id: 在一个大的查询语句中每个SELECT关键字都对应一个唯一的id
- select_type: SELECT关键字对应的那个查询的类型
- table 表名
- partitions: 匹配的分区信息
- type: 针对单表的访问方法
- possible_keys: 可能用到的索引
- key: 实际上使用的索引
- key_len: 实际使用到的索引长度
- ref: 当使用索引列等值查询时,与索引列进行等值匹配的对象信息
- rows: 预估的需要读取的记录条数
- filtered: 某个表经过搜索条件过滤后剩余记录条数的百分比
- Extra: 一些额外的信息
Spring
IOC AOP原理
- IOC : 工厂+反射
- AOP: 动态代理+责任链拦截器 有接口-JDK动态代理 无接口-CGlib
ioc初始化过程
加载配置文件—通过Resource定位BeanDefinition—-存入DefaultListableBeanFactory—通过loadBeanDefinitions()来完成BeanDefinition信息的载入—将抽象好的BeanDefinition注册到IoC容器中
Spring Bean 生命周期(实例化Bean过程)
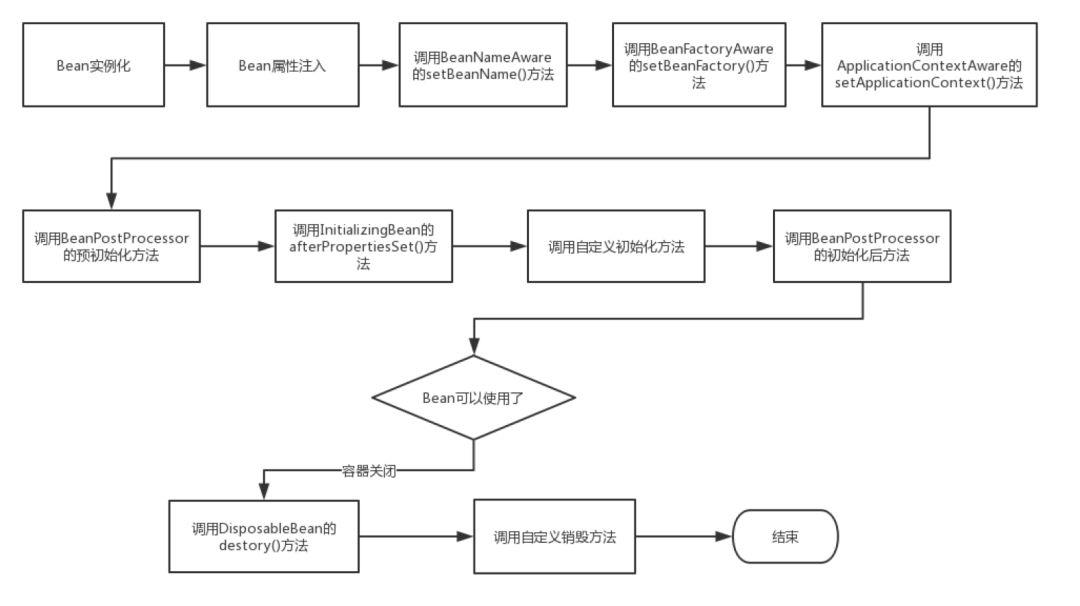
- 实例化对象;
- 填充属性值及引用;
- 调用
BeanNameAware的setBeanName(String name)设置 bean 的 id; - 调用
BeanFactoryAware的setBeanFactory(BeanFactory beanFactory)设置BeanFactoryBean工厂; - 同上:
ApplicationContextAware`setApplicationContext(ApplicationContext applicationContext)`; - 如果实现
BeanPostProcessor,则 调用 postProcessBeforeInitialization() 初始化前的后置处理方法 - 如果实现了
InitializingBean接口,则使用afterPropertiesSet()来初始化属性 - 如果实现
BeanPostProcessor,则 调用 postProcessAfterInitialization() 初始化后的后置处理方法 - 此时,bean 就可以使用了
DisposableBean接口destroy()销毁bean。不过在Spring5.0开始
Mybatis
Mybatis 中 $ 与 # 的区别
$相当于对数据加上双引号,$则是什么就显示什么
如:id = #{id},如果传入的值是99,那么解析成sql时的值为 id =“99”
如:id = ${id},如果传入的值是99,那么解析成sql时的值为d = 99
$方式一般用于传入数据库对象,例如传入表名
活order b动态排序
Mybatis 缓存
一级缓存:一级缓存是SQLSession级别的,SqlSession对象中有一个HashMap用于存储缓存数据,不同的SqlSession之间缓存数据区域(HashMap)是互相不影响的。Mybatis默认开启一级缓存,不需要进行任何配置。
当在同一个SqlSession中执行两次相同的sql语句时,第一次执行完毕会将数据库中查询的数据写到缓存(内存)中,第二次查询时会从缓存中获取数据,不再去底层进行数据库查询,如果SqlSession执行了DML操作(insert、update、delete),并执行commit()操作,mybatis则会清空SqlSession中的一级缓存
- 二级缓存:二级缓存是mapper级别的缓存。其作用域是mapper的同一个namespace,不同的SqlSession两次执行相同的namespace下的sql语句,且向sql中传递的参数也相同,即最终执行相同的sql语句,则第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次查询时会从缓存中获取数据,不再去底层数据库查询,从而提高查询效率。
Mybatis默认没有开启二级缓存,需要在setting全局参数中配置开启二级缓存。
Mybatis Mapper/Dao接口工作原理
Mapper接口全限定名对应映射文件中的namespace的值,Mapper接口的方法名对应映射文件中SQL的id值,接口方法内的参数对应应映射文件中SQL的paramType值,接口方法返回值对应映射文件中的SQL的resultMap/result。
Mapper接口是没有实现类的,当调用接口方法时,接口全限名+方法名拼接字符串作为key值,可唯一定位一个MapperStatement。
SpringMVC
SpringMVC执行流程
- 用户向服务器发送请求,请求被SpringMVC的前端控制器DispatcherServlet拦截
- DispatcherServlet对请求URL进行解析,调用HandlerMapping获得该Handler配置的所有相关对象,包括Handler对象以及Handler对象对应的拦截器,这些对象被封装到一个HandlerExecutionchain当中返回
- DispatcherServlet根据获得的Handler(Controller),选择一个合适的HandlerAdapter。一个HandlerAdapter会被用于处理多种(一类)Handler,并调用Handler实际处理请求的方法。
- 在调用Handler实际处理请求的方法之前,HandlerAdapter首先会结合用户配置对请求消息进行转换(序列化),然后通过DataBinder将请求中的模型数据绑定到Handler对应的处理方法的参数中。
- Handler调用业务逻辑组件完成对请求的处理后,向DispatcherServlet返回一个ModelAndView对象,ModelAndView对象中应该包含视图名或者视图和模型。
- DispatcherServlet调用视图解析器ViewResolver结合Model来渲染视图
- DispatcherServlet将视图渲染结果返回给客户端
SpringBoot
SpringBoot自动装配原理
@SpringBootApplication----@EnableAutoConfiguration---@Import({AutoConfigurationImportSelector.class})
AutoConfigurationImportSelector类中的selectImports方法执行完毕后,Spring会把这个方法返回的类的全限定名数组里的所有的类都注入到IOC容器中
多线程,并发与锁
synchronized原理
代码块的同步是利用monitorenter和monitorexit这两个字节码指令。它们分别位于同步代码块的开始和结束位置。当jvm执行到monitorenter指令时,当前线程试图获取monitor对象的所有权,如果未加锁或者已经被当前线程所持有,就把锁的计数器+1;当执行monitorexit指令时,锁计数器-1;当锁计数器为0时,该锁就被释放了。如果获取monitor对象失败,该线程则会进入阻塞状态,直到其他线程释放锁。
synchronized修饰的方法并没有monitorenter指令和monitorexit指令,取得代之的确实是ACC_SYNCHRONIZED标识,该标识指明了该方法是一个同步方法,当方法调用时,调用指令将会 检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先持有monitor, 然后再执行方法,最后再方法完成(无论是正常完成还是非正常完成)时释放monitor。
Lock/AQS原理
CountDownLatch
Java的concurrent包里面的CountDownLatch其实可以把它看作一个计数器,只不过这个计数器的操作是原子操作,同时只能有一个线程去操作这个计数器,也就是同时只能有一个线程去减这个计数器里面的值。
你可以向CountDownLatch对象设置一个初始的数字作为计数值,任何调用这个对象上的await()方法都会阻塞,直到这个计数器的计数值被其他的线程减为0为止。
CountDownLatch的一个非常典型的应用场景是:有一个任务想要往下执行,但必须要等到其他的任务执行完毕后才可以继续往下执行。假如我们这个想要继续往下执行的任务调用一个CountDownLatch对象的await()方法,其他的任务执行完自己的任务后调用同一个CountDownLatch对象上的countDown()方法,这个调用await()方法的任务将一直阻塞等待,直到这个CountDownLatch对象的计数值减到0为止。
volatile 原理
可见性:对volatile变量进行写操作的时候,JVM会向处理器发送一条lock前缀的指令,将这个本地内存中的变量同步到系统主内存中。对于其他线程,volatile变量在每次使用之前都从主内存刷新
有序性:禁止指令重排序(编译器对操作volatile的变量不再进行优化)
集合
ConcurrentHashMap
原理
- 1.7 : Segment + HashEntry ,Segment 继承ReentrantLock—–tryLock()+自旋获取锁,超过指定次数就挂起,等待唤醒 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值(读不加锁)。
- 1.8 : Node + CAS + Synchronized+红黑树 Node中的
val next都用了 volatile 修饰 ,读就不用加锁
多线程下如何确定size
1.7 :
首先他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的
如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回
1.8 :
Linux
linux 常用命令
微服务
dubbo跟feign区别
Duoob:RPC—底层 TCP(TCP连接一旦建立,在通信双方中的任何一方主动关闭连 接之前,TCP 连接都将被一直保持下去)
Feign:REST—底层 HTTP(HTTP在每次请求结束后都会主动释放连接)



