摘要
在 Java 并发编程中,要想使并发程序能够正确地执行,必须要保证三条原则,即:原子性、可见性和有序性。只要有一条原则没有被保证,就有可能会导致程序运行不正确。volatile关键字 被用来保证可见性,即保证共享变量的内存可见性以解决缓存一致性问题。一旦一个共享变量被 volatile关键字 修饰,那么就具备了两层语义:内存可见性和禁止进行指令重排序。在多线程环境下,volatile关键字 主要用于及时感知共享变量的修改,并使得其他线程可以立即得到变量的最新值,例如,用于 修饰状态标记量 和 Double-Check (双重检查)中。
volatile关键字 虽然从字面上理解起来比较简单,但是要用好不是一件容易的事情。由于 volatile关键字 是与 内存模型 紧密相关,因此在讲述 volatile关键字 之前,我们有必要先去了解与内存模型相关的概念和知识,然后回头再分析 volatile关键字 的实现原理,最后在给出 volatile关键字 的使用场景。
内存模型的相关概念
大家都知道,计算机在执行程序时,每条指令都是在 CPU 中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题:由于 CPU 执行速度很快,而从内存读取数据和向内存写入数据的过程跟 CPU 执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此,在 CPU 里面就有了 高速缓存(寄存器)。
也就是说,在程序运行过程中,会将运算需要的数据从主存复制一份到 CPU 的高速缓存当中,那么, CPU 进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i + 1;
当线程执行这个语句时,会先从主存当中读取 i 的值,然后复制一份到高速缓存当中,然后CPU执行指令对 i 进行加1操作,然后将数据写入高速缓存,最后将高速缓存中 i 最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核 CPU 中,每个线程可能运行于不同的 CPU 中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如,同时有两个线程执行这段代码,假如初始时 i 的值为 0,那么我们希望两个线程执行完之后 i 的值变为 2。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取 i 的值存入各自所在的 CPU 的高速缓存当中,然后线程1 进行加 1 操作,然后把 i 的最新值 1 写入到内存。此时线程 2 的高速缓存当中 i 的值还是 0,进行加 1 操作之后,i 的值为 1,然后线程 2 把 i 的值写入内存。
最终结果 i 的值是 1,而不是 2 。这就是著名的 缓存一致性问题 。通常称这种被多个线程访问的变量为 共享变量 。
也就是说,如果一个变量在多个 CPU 中都存在缓存(一般在多线程编程时才会出现),那么就可能存在 缓存不一致 的问题。
为了解决缓存不一致性问题,在 硬件层面 上通常来说有以下两种解决方法:
- 通过在 总线加 LOCK# 锁 的方式 (在软件层面,效果等价于使用 synchronized 关键字);
- 通过 缓存一致性协议 (在软件层面,效果等价于使用 volatile 关键字)。
在早期的 CPU 当中,是通过在总线上加 LOCK# 锁的形式来解决缓存不一致的问题。因为 CPU 和其他部件进行通信都是通过总线来进行的,如果对总线加 LOCK# 锁的话,也就是说阻塞了其他 CPU 对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中, 如果一个线程在执行 i = i + 1,如果在执行这段代码的过程中,在总线上发出了 LCOK# 锁的信号,那么只有等待这段代码完全执行完毕之后,其他 CPU 才能从变量 i 所在的内存读取变量,然后进行相应的操作,这样就解决了缓存不一致的问题。但是上面的方式会有一个问题,由于在锁住总线期间,其他 CPU 无法访问内存,导致效率低下。
所以,就出现了 缓存一致性协议 ,其中最出名的就是 Intel 的 MESI 协议。MESI 协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是: 当 CPU 写数据时,如果发现操作的变量是共享变量,即在其他 CPU 中也存在该变量的副本,会发出信号通知其他 CPU 将该变量的缓存行置为无效状态。因此,当其他 CPU 需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
并发编程中的三个概念
原子性
原子性: 即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
可见性
可见性: 指当多个线程访问同一个共享变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
举个简单的例子,看下面这段代码:
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;
假若执行 线程1 的是 CPU1,执行 线程2 的是 CPU2。由上面的分析可知,当 线程1 执行 i = 10 这句时,会先把 i 的初始值加载到 CPU1 的高速缓存中,然后赋值为10,那么在 CPU1 的高速缓存当中 i 的值变为 10 了,却没有立即写入到主存当中。此时,线程2 执行 j = i,它会先去主存读取 i 的值并加载到 CPU2 的缓存当中,注意此时内存当中 i 的值还是 0,那么就会使得 j 的值为 0,而不是 10。
这就是可见性问题,线程1 对变量 i 修改了之后,线程2 没有立即看到 线程1 修改后的值。
有序性
有序性:即程序执行的顺序按照代码的先后顺序执行。
- 指令重排序:处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的(单线程情形下)。指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性
这段代码有4个语句,那么可能的一个执行顺序是:2 → 1 → 3 → 4 这就是指令重排序int a = 10; //语句1 int r = 2; //语句2 a = a + 3; //语句3 r = a*a; //语句4
那么可不可能是这个执行顺序呢:2 → 1 → 4 → 3
答案是不可能,因为处理器在进行重排序时会考虑指令之间的数据依赖性,如果一个指令 Instruction 2 必须用到 Instruction 1 的结果,那么处理器会保证 Instruction 1 会在 Instruction 2 之前执行。java
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
上面代码中,由于 语句1 和 语句2 没有数据依赖性,因此可能会被重排序。假如发生了重排序,在 线程1 执行过程中先执行 语句2,而此时 线程2 会以为初始化工作已经完成,那么就会跳出 while循环 ,去执行 doSomethingwithconfig(context) 方法,而此时 context 并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。也就是说,要想使并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
## Java内存模型
在 Java虚拟机规范 中,试图定义一种 Java内存模型(Java Memory Model,JMM) 来屏蔽各个硬件平台和操作系统的内存访问差异,以实现让 Java 程序在各种平台下都能达到一致的内存访问效果。在此之前,主流程序语言(c/c++)直接使用物理硬件和操作系统的内存模型,因此会由于不同平台上内存模型的差异,有可能导致程序在一套平台上并发完全正常,而在另一套平台上并发访问却经常出错。
Java内存模型 规定所有的变量都是存在主存当中(类似于前面说的物理内存),每个线程都有自己的工作内存(类似于前面的高速缓存)。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作,并且每个线程不能访问其他线程的工作内存。
举个简单的例子:在java中,执行下面这个语句:
````java
i = 10;
执行线程必须先在自己的工作线程中对 变量i 所在的缓存进行赋值操作,然后再写入主存当中,而不是直接将数值10写入主存当中。
这里讲的主内存,工作内存与Java内存区域中的Java堆、栈、方法区等并不是同一个层次的内存划分,这两者基本上是没有关系的,如果两者一定要勉强对应起来,那主内存对应于Java堆中的对象实例数据 部分,而工作内存则对应于虚拟机栈中的部分区域。
内存交互操作
关于主内存与工作内存之间具体的交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步回主内存之类的实现细节,Java内存模型中定义了以下8种操作来完成
lock(锁定): 作用与主内存的变量,它把一个变量标识为一条线程独占的状态。
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中
load(载入):作用于工作内存的变量,它把read操作从主内存得到的变量放入工作内存的变量副本中
use(使用):作用于工作内存的变量,它把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用到变量的值的字节码指令时将会执行这个操作
assign(赋值):作用于工作内存的变量他把 一个从执行引擎接收到的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作
store(存储):作用于 工作内存的变量,它把工作内存中一个变量的值传送到主内存中,以便随后write操作使用
write(写入):作用于主内存的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中
原子性
由Java内存模型来直接保证原子性变量操作包括 read,load,assign,use,store,write,我们大致可以认为 基本数据类型的访问读写是具备原子性的(读+写就不是了)
如果要实现更大范围操作的原子性,可以通过 synchronized 和 Lock 来实现。由于 synchronized 和 Lock 能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
可见性
对于可见性,Java 提供了 volatile关键字 来保证可见性。
当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过 synchronized 和 Lock 也能够保证可见性,synchronized 和 Lock 能保证同一时刻只有一个线程获取锁然后执行同步代码,并且 在释放锁之前会将对变量的修改刷新到主存当中,因此可以保证可见性。
有序性
Java中天然的有序性可以总结为一句话:如果在本线程中观察,所有的操作都是有序的,如果在一个线程中观察另一个线程,所有的操作都是无序的。前半句是指”线程内 表现为串行的语句”,后半句是指指令重排序现象和工作内存与主内存同步延迟现象
在 Java 中,可以通过 volatile 关键字来保证一定的“有序性”(具体原理在下一节讲述)。另外,我们千万不能想当然地认为,可以通过synchronized 和 Lock 来保证有序性,也就是说,不能由于 synchronized 和 Lock 可以让线程串行执行同步代码,就说它们可以保证指令不会发生重排序,这根本不是一个粒度的问题。
volatile
volatile关键字的两层语义
一旦一个共享变量(类的成员变量、类的静态成员变量)被 volatile 修饰后,那么就具备了两层语义:
- 保证了不同线程对共享变量进行操作时的可见性,即一个线程修改了某个变量的值,这个新值对其他线程来说是 立即可见 的;
禁止进行指令重排序,即保证有序性
volatile不保证原子性
java
//线程类
class MyThread extends Thread {
// volatile 共享静态变量,类成员
public volatile static int count;private static void addCount() {
for (int i = 0; i < 100; i++) { count++; } System.out.println("count=" + count);}
@Override
public void run() {addCount();}
}
//测试类
public class Run {
public static void main(String[] args) {
//创建 100个线程并启动
MyThread[] mythreadArray = new MyThread[100];
for (int i = 0; i < 100; i++) {
mythreadArray[i] = new MyThread();
}
for (int i = 0; i < 100; i++) {
mythreadArray[i].start();
}
}
}/ Output(循环):
… …
count=9835
///:~
大家想一下这段程序的输出结果是多少?也许有些朋友认为是 10000。但是事实上运行它会发现每次运行结果都不一致,都是一个 小于 10000 的数字。可能有的朋友就会有疑问,不对啊,上面是对变量 count 进行自增操作,由于 volatile 保证了可见性,那么在每个线程中对 count 自增完之后,在其他线程中都能看到修改后的值啊,所以有 100个 线程分别进行了 100 次操作,那么最终 count 的值应该是 100*100=10000。
这里面就有一个误区了,volatile 关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。可见性只能保证每次读取的是最新的值,但是 volatile 没办法保证对变量的操作的原子性。在前面已经提到过,自增操作是不具备原子性的,它包括 读取变量的原始值、进行加1操作 和 写入工作内存 三个原子操作。那么就是说,这三个子操作可能会分割开执行,所以就有可能导致下面这种情况出现:
假如某个时刻 变量count 的值为 10,线程1 对变量进行自增操作,线程1 先读取了 变量count 的原始值,然后 线程1 被阻塞了;然后,线程2 对变量进行自增操作,线程2 也去读取 变量count 的原始值,由于 线程1 只是对 变量count 进行读取操作,而没有对变量进行修改操作,所以不会导致 线程2 的工作内存中缓存变量 count 的缓存行无效,所以 线程2 会直接去主存读取 count的值 ,发现 count 的值是 10,然后进行加 1 操作。注意,此时 线程2 只是执行了 count + 1 操作,还没将其值写到 线程2 的工作内存中去!此时线程2 被阻塞,线程1 进行加 1 操作时,注意操作数count仍然是 10!然后,线程2 把 11 写入工作内存并刷到主内存。虽然此时 线程1 能感受到 线程2 对count的修改,但由于线程1只剩下对count的写操作了,而不必对count进行读操作了,所以此时 线程2 对count的修改并不能影响到 线程1。于是,线程1 也将 11 写入工作内存并刷到主内存。也就是说,两个线程分别进行了一次自增操作后,count 只增加了 1。
### 使用volatile关键字的场景
synchronized 关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率;而 volatile 关键字在某些情况下性能要优于 synchronized,但是要注意 volatile 关键字是无法替代 synchronized 关键字的,因为 volatile 关键字无法保证操作的原子性。通常来说,使用 volatile 必须具备以下两个条件:
* 对变量的写操作不依赖于当前值;
* 该变量没有包含在具有其他变量的不变式中。
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值 独立于任何程序的状态,包括变量的当前状态。事实上,上面的两个条件就是保证对 该volatile变量 的操作是原子操作,这样才能保证使用 volatile关键字 的程序在并发时能够正确执行。
特别地,关键字 volatile 主要使用的场合是:
在多线程环境下及时感知共享变量的修改,并使得其他线程可以立即得到变量的最新值。
#### 状态标记量
````java
// 示例 1
volatile boolean flag = false;
while(!flag){
doSomething();
}
public void setFlag() {
flag = true;
}
// 示例 2
volatile boolean inited = false;
//线程1:
context = loadContext();
inited = true;
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
Double-Check (双重检查)
class Singleton{
private volatile static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}
小结
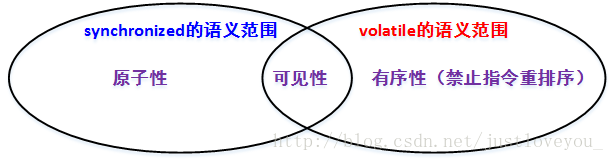
关键字volatile 与内存模型紧密相关,是线程同步的轻量级实现,其性能要比 synchronized关键字 好。在作用对象和作用范围上, volatile 用于修饰变量,而 synchronized关键字 用于修饰方法和代码块,而且 synchronized 语义范围不但包括 volatile拥有的可见性,还包括volatile 所不具有的原子性,但不包括 volatile 拥有的有序性,即允许指令重排序。因此,在多线程环境下,volatile关键字 主要用于及时感知共享变量的修改,并保证其他线程可以及时得到变量的最新值